
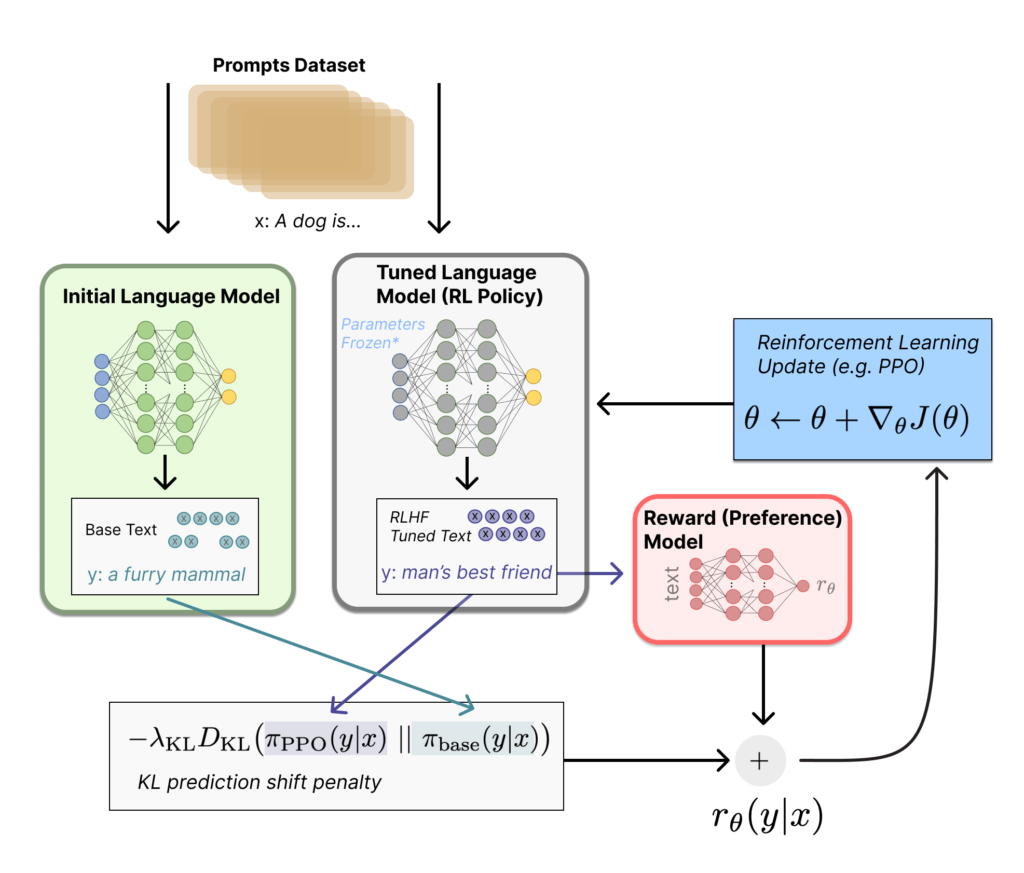
In this episode, we dive into the not-so-secret sauce of ChatGPT, and what makes it a different model than its predecessors in the field of NLP and Large Language Models.
We explore how human feedback can be used to speed up the learning process in reinforcement learning, making it more efficient and effective.
Whether you’re a machine learning practitioner, researcher, or simply curious about how machines learn, this episode will give you a fascinating glimpse into the world of reinforcement learning with human feedback.
Sponsors
This episode is supported by How to Fix the Internet, a cool podcast from the Electronic Frontier Foundation and Bloomberg, global provider of financial news and information, including real-time and historical price data, financial data, trading news, and analyst coverage.
References
Learning through human feedback
https://www.deepmind.com/blog/learning-through-human-feedback
Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback
