
The two most widely considered software development models in modern project management are, without any doubt, the Waterfall Methodology and the Agile Methodology. Should one adopt waterfall or agile in machine learning?
While this is not a post that exhaustively explains the two models, generally speaking the Waterfall approach is the way to go for certain areas of engineering design. Especially those in which it is accepted to have progress flowing in one direction (hence the name waterfall).
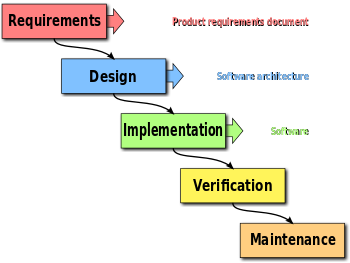
Schema of a typical waterfall methodology
Software development purists look at the Waterfall methodology as the model to look at for highly structured projects e.g. Operating System design, real-time codecs, scientific software or software for critical environments.
For AI and machine learning projects however, this approach can be deleterious and lead to longer development cycles and project failure. Below there is a table that not only summarises some differences between the two methodologies, but also emphasises the major reasons why Agile is probably the best development method for data science projects.
A comparison between waterfall and agile in machine learning
WATERFALL |
AGILE |
| Sequential | Iterative |
| Requirements clear from the beginning | Even if the customer’s scope is well defined, the requirements evolve and tend to change during the course of the project |
| Fixed plan | Adaptable plan to better accommodate business needs and continuous feedbacks |
| Inflexible to changes | Only general milestones are created that describe where the project should head |
| Deliver product that has been planned | Create minimal viable product (MVP) as fast as possible, so that business users can play with it and provide feedback |
| Project is divided into successive phases, which are not revisited once completed | Project is divided in 2 weeks iterative sprints and one can go back and forth between sprints until completion |
| Tests are done at the end | Tests are performed throughout the project |
| Participation of business users is not required | Business users are involved throughout the development phase to regulate users’ needs and priorities |
| Precise cost and time estimation | Difficult to know beforehand how many sprints are needed to achieve requirements |
| Algorithms are developed after requirements have been gathered | Algorithms are developed immediately |
| Simple to give updates to the management and business teams, due to detailed planning and accurate budget estimations | Hard to update all parties especially when they are not deeply involved |
| Does not work well for the data discovery process due to the cyclical nature of the latter | Suitable to data science projects, which comprise multiple iterations of understanding a business problem by asking questions, data acquisition from multiple sources, data cleaning, feature engineering and modelling |
| Fail slow: only towards the end of the project one knows if all KPIs have been reached | Fail fast, e.g. if model performance is 70% and the minimum valuable performance is 90% the project can be stopped earlier since it is unlikely that the goal will be reached any time soon |
| A model is deployed only at the end of the project | Model deployment occurs as soon as an acceptable enough model has been designed and validated |
